Machine Learning Là Gì? Thuật Toán Và Ứng Dụng Của Machine Learning
Trí tuệ nhân tạo (AI), cụ thể là Machine Learning đang được ứng dụng rộng rãi trong mọi lĩnh vực của đời sống. Vậy Machine Learning là gì và được sử dụng như thế nào? Mời bạn đọc tham khảo các nội dung chi tiết thông qua bài viết dưới đây.
1. Machine Learning là gì?
Có rất nhiều cách giải thích khác nhau về Machine Learning. Thế nhưng, bạn có thể hiểu theo nghĩa đơn giản như sau: Machine learning là một nhánh của trí tuệ nhân tạo AI. Lĩnh vực này cho phép máy tính có khả năng cải thiện bản thân dựa trên dữ liệu hoặc kinh nghiệm có sẵn. Điều tuyệt vời của Machine Learning là nó có thể tự dự đoán hoặc đưa ra một quyết định cụ thể nào đó mà không cần lập trình cụ thể.
Machine Learning được chia làm 2 loại là phân loại (Classification) và dự đoán (Prediction). Dự đoán có thể bao gồm dự đoán giá xe, giá nhà, dự đoán về cổ phiếu, chứng khoán.
Phân loại có thể bao gồm nhận diện đồ vật, nhận diện chữ viết tay.

Machine Learning là gì?
2. Sự ra đời của Machine Learning
Machine Learning được xem là một trong những nghiên cứu lâu đời trong lĩnh vực cộng tác học máy. Nó đã được phát triển từ những nghiên cứu trước đó trong lĩnh vực học máy, trí tuệ nhân tạo và những nghiên cứu trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Sự ra đời của Machine Learning được coi là đầu tiên tại Mỹ vào những năm 1950 với nghiên cứu của các nhà khoa học như Arthur Samuel và các nhà khoa học khác. Samuel đã phát triển một chương trình máy tính đầu tiên có thể học chơi cờ vua.
Từ đó, Machine Learning đã tiếp tục phát triển và mở rộng, đặc biệt là trong gần hai thập kỷ qua, khi sự phát triển của máy tính và dữ liệu đã cho phép cho việc học máy trở nên hiệu quả và dễ dàng hơn bao giờ hết.
Hiện nay, Machine Learning đang được sử dụng rộng rãi trong nhiều lĩnh vực, bao gồm từ xử lý ngôn ngữ tự nhiên, trí tuệ nhân tạo, xử lý hình ảnh, cảnh báo sức khỏe và nhiều lĩnh vực khác.
Trở thành chuyên gia AI với GPT-4 bằng cách đăng ký học online ngay. Khóa học giúp bạn biết cách kết hợp ChatGPT với các công cụ AI khác để làm content marketing, làm ảnh, làm video, làm nhạc melody, mixing....Đăng ký ngay.



3. Machine Learning hoạt động như thế nào?
Machine Learning hoạt động theo hai cách chính: supervised learning và unsupervised learning.
- Supervised Learning: Trong hình thức học có giám sát này, máy tính được cung cấp với một tập dữ liệu có nhãn, và nhiệm vụ của nó là học từ dữ liệu này và dự đoán nhãn cho các dữ liệu mới. Ví dụ, nếu chúng ta có một tập dữ liệu gồm các hình ảnh của quần áo với nhãn "Áo" hoặc "Quần", máy tính sẽ học từ tập dữ liệu này và sau đó có thể dự đoán nhãn cho các hình ảnh mới mà nó chưa từng nhìn thấy.
- Supervised Learning sử dụng một số phương pháp như: Linear regression, neural networks, logistic regression, random forest, naive bayes, support vector, logistic regression…
- Unsupervised Learning: Trong hình thức học không có giám sát này, máy tính không được cung cấp với bất kỳ nhãn nào và nhiệm vụ của nó là tìm kiếm mẫu hoặc cấu trúc trong dữ liệu. Ví dụ, nếu chúng ta có một tập dữ liệu gồm các giá trị dữ liệu về mức độ hài lòng của khách hàng với một sản phẩm, máy tính có thể sử dụng phương pháp học không có giám sát để tìm ra các nhóm khách hàng có mức độ hài lòng tương tự.
4. Phân loại Machine Learning
Có nhiều loại Machine Learning, nhưng chúng ta có thể chia chúng thành ba phân loại chính sau:
- Supervised Learning: Đây là dạng học máy phổ biến nhất, trong đó máy tính được huấn luyện với một tập dữ liệu có nhãn và sử dụng kết quả đó để dự đoán nhãn cho dữ liệu mới. Ví dụ, phân loại hình ảnh và dự đoán giá của một căn nhà là ví dụ của Supervised Learning.
- Unsupervised Learning: Đây là dạng học máy không có nhãn, trong đó máy tính sẽ tìm kiếm mẫu hoặc cấu trúc trong dữ liệu mà không có sự giám sát của người dùng. Ví dụ, phân loại các khách hàng theo nhóm và tìm kiếm cấu trúc trong dữ liệu là ví dụ của Unsupervised Learning.
- Reinforcement Learning: Đây là dạng học máy giúp máy tính học từ kinh nghiệm của mình và tự điều chỉnh hành vi của mình theo thời gian. Ví dụ, điều khiển một đội bóng đá hoặc điều khiển động cơ xe tự lái là ví dụ của Reinforcement Learning.
- Transfer learning: Sử dụng các kiến thức đã học được từ các mô hình có hiệu quả cao và sử dụng chúng để giúp huấn luyện các mô hình mới với tập dữ liệu nhỏ hơn hoặc mới hơn. Điều này giúp tiết kiệm thời gian và chi phí huấn luyện mô hình mới, cải thiện độ chính xác của mô hình. Transfer learning được sử dụng rộng rãi trong các ứng dụng xử lý ngôn ngữ tự nhiên, phân loại ảnh và nhận dạng giọng nói.
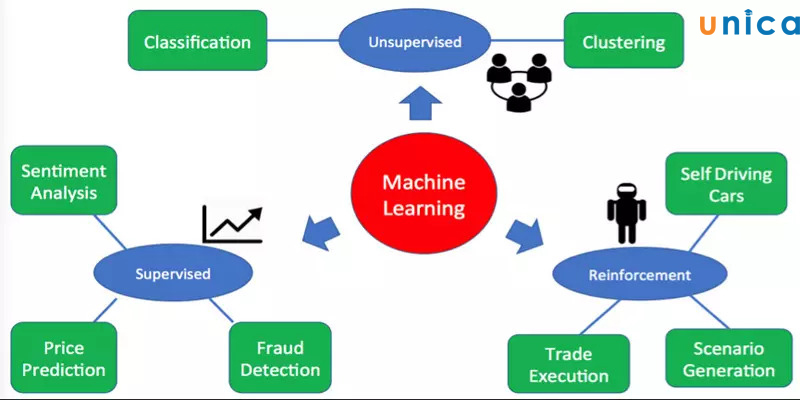
Phân loại Machine Learning
5. Machine Learning khác Deep Learning ở điểm nào
Machine Learning và Deep Learning là 2 lĩnh vực khoa học liên quan đến trí tuệ nhân tạo. Thế nhưng, chúng có những điểm khác biệt như sau:
Machine Learning và Deep Learning là hai khoa học liên quan đến trí tuệ nhân tạo, nhưng có một số sự khác biệt chính giữa hai:
- Phạm vi: Machine Learning là một rộng hơn Deep Learning, bao gồm nhiều loại học máy khác nhau như Supervised Learning, Unsupervised Learning, và Reinforcement Learning. Deep Learning lại là một phần của Machine Learning, chủ yếu được sử dụng cho các bài toán phân loại hoặc giải quyết vấn đề.
- Cấu trúc: Machine Learning thường sử dụng các thuật toán đơn giản như k-Nearest Neighbors, Decision Trees, và Naive Bayes. Deep Learning sử dụng các mạng nơ-ron sâu để xử lý dữ liệu và dự đoán kết quả.
- Dữ liệu: Machine Learning có thể hoạt động với dữ liệu cấu trúc hoặc không cấu trúc, nhưng Deep Learning chủ yếu hoạt động với dữ liệu hình ảnh, âm thanh, và dữ liệu không gian.
Tóm lại, Deep Learning là một phần của Machine Learning với mục đích giải quyết các bài toán phức tạp hơn bằng cách sử dụng mạng nơ-ron sâu.
6. Các thuật toán phổ biến của Machine Learning
6.1. Linear Regression (Hồi quy tuyến tính)
Linear Regression là một thuật toán trong Machine Learning dùng để dự đoán mối quan hệ giữa một biến định lượng (biến đầu vào) và một biến định lượng khác (biến đầu ra). Nó cố gắng tìm một đường thẳng (hàm tuyến tính) phù hợp nhất để mô tả quan hệ giữa hai biến.
Cách hoạt động của Linear Regression:
- Chuẩn bị dữ liệu: Trước hết, chúng ta cần chuẩn bị tập dữ liệu gồm các cặp giá trị biến đầu vào và biến đầu ra.
- Xác định hàm tuyến tính: Tiếp theo, chúng ta sử dụng các công thức để tìm ra hàm tuyến tính phù hợp nhất. Hàm tuyến tính có dạng y = b0 + b1x, trong đó y là biến đầu ra, x là biến đầu vào, b0 là hệ số tự do, và b1 là hệ số tuyến tính.
- Ước lượng hệ số: Sau đó, chúng ta sử dụng các phương pháp tính toán để ước lượng giá trị của b0 và b1 dựa trên dữ liệu.
- Sử dụng hàm tuyến tính để dự đoán: Cuối cùng, chúng ta có thể sử dụng hàm tuyến tính để dự đoán điều mà mình muốn dự đoán.
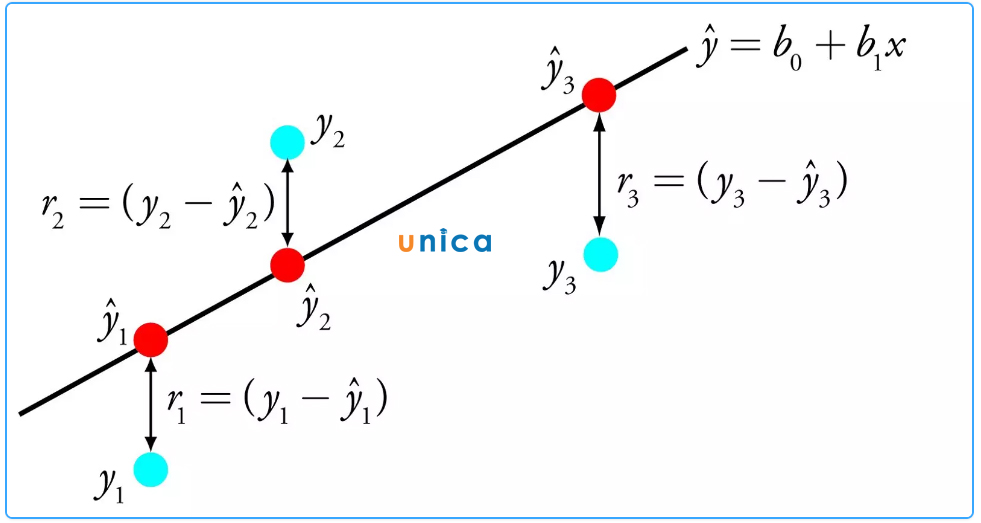
Linear Regression (Hồi quy tuyến tính)
6.2. Logicstic Regression (Hồi quy logistic)
Logistic Regression là một thuật toán phân loại của Machine Learning, dùng để dự đoán xác suất một mục tiêu thuộc về một nhóm nào đó. Nó được sử dụng rộng rãi trong nhiều lĩnh vực, bao gồm marketing, bảo mật, y tế và nhiều hơn nữa.
Cách hoạt động của Logistic Regression là tính toán một hàm số logistic, sử dụng các đặc trưng đầu vào để dự đoán xác suất một mục tiêu thuộc về một nhóm nào đó. Hàm số logistic có dạng một đường cong s-shaped, với giá trị đầu ra trong khoảng từ 0 đến 1, mà có thể được hiểu như là xác suất một mục tiêu thuộc về một nhóm nào đó.
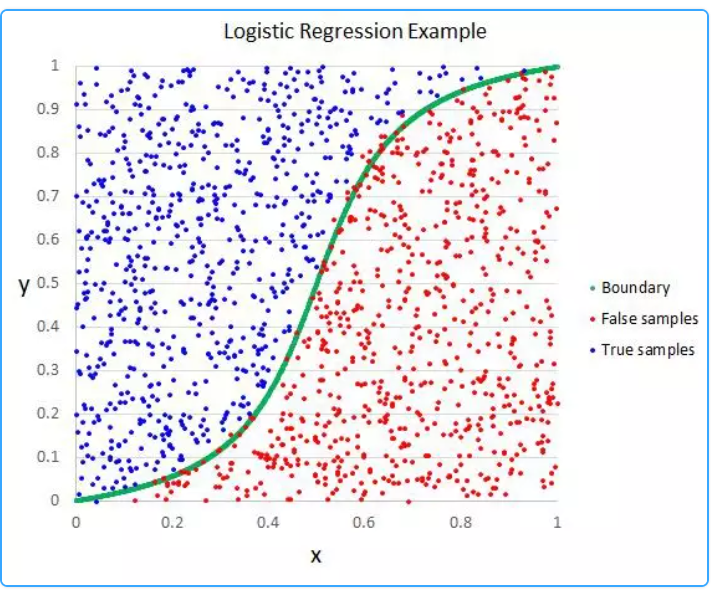
Thuật toán Logistic Regression
6.3. Decision Tree (Cây quyết định)
Decision Tree là một thuật toán trong Machine Learning dùng để phân tích và dự đoán dữ liệu dựa trên các quyết định liên tiếp về các biến đầu vào. Nó tạo ra một cây quyết định bằng cách chia nhỏ tập dữ liệu thành nhiều phần và tìm các điểm phân chia tốt nhất giữa các biến.
Cách hoạt động của Decision Tree:
- Chọn biến đầu vào: Trước hết, chúng ta phải chọn biến đầu vào từ tập dữ liệu để phân tích.
- Tìm điểm phân chia tốt nhất: Tiếp theo, chúng ta sử dụng các phương pháp tính toán để tìm điểm phân chia tốt nhất giữa các biến đầu vào.
- Tạo nhánh cho cây quyết định: Sau khi tìm được điểm phân chia, chúng ta tạo nhánh cho cây quyết định và tiếp tục phân tích cho mỗi nhánh mới.
- Tiếp tục phân tích cho từng nhánh: Quá trình phân tích tiếp tục cho từng nhánh cho đến khi nhánh đó không còn thể chia nữa hoặc đạt đến một điều kiện dừng.
- Dự đoán: Cuối cùng, chúng ta có thể đưa ra kết quả dự đoán.
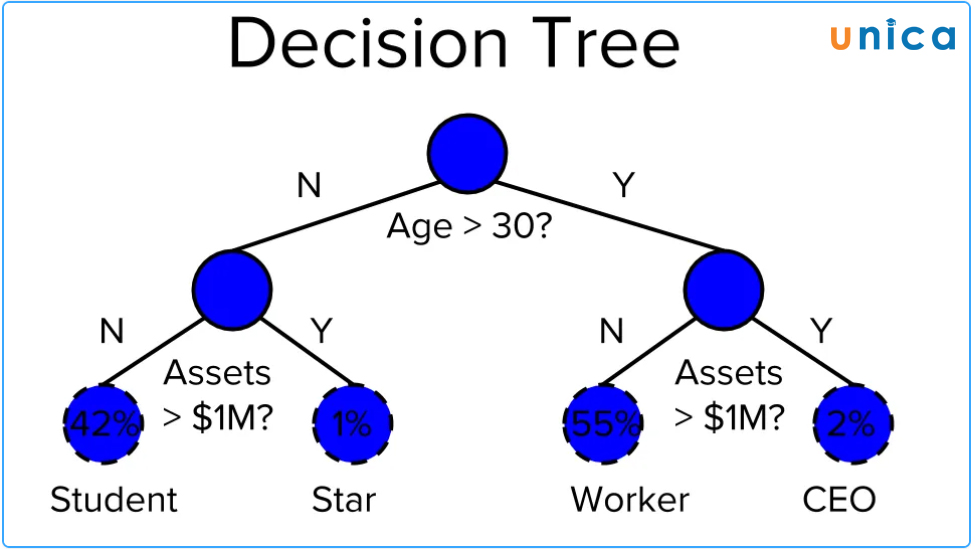
Decision Tree (Cây quyết định)
6.4. Thuật toán Support Vector Machine (Thuật toán SMV)
Thuật toán SVM được dùng với mục đích phân loại. Với thuật toán này, bạn sẽ vẽ biểu đồ dữ liệu thô dưới dạng các điểm trong không gian N chiều (với n là đối tượng mà bạn đang có). Sau đó, giá trị của mỗi đối tượng sẽ được gắn với tọa độ cụ thể, giúp bạn phân loại dữ liệu một cách dễ dàng. Các dòng này là bộ phận loại có thể sử dụng để tách dữ liệu và vẽ chúng trên biểu đồ.
Cách hoạt động của SVM:
- Chuyển đổi dữ liệu: Trước hết, chúng ta phải chuyển đổi dữ liệu đầu vào sang một không gian mới để cho phép SVM tìm hyperplane phân chia tốt nhất.
- Tìm hyperplane phân chia tốt nhất: Tiếp theo, chúng ta sử dụng các phương pháp tính toán để tìm hyperplane phân chia tốt nhất giữa các lớp dữ liệu.
- Xác định điểm dữ liệu quan trọng: SVM sẽ tìm các điểm dữ liệu quan trọng nằm gần hyperplane phân chia và gọi chúng là các "support vectors".
- Dự đoán: Cuối cùng, chúng ta sử dụng hyperplane phân chia và các support vectors để dự đoán lớp dữ liệu cho các điểm dữ liệu mới.
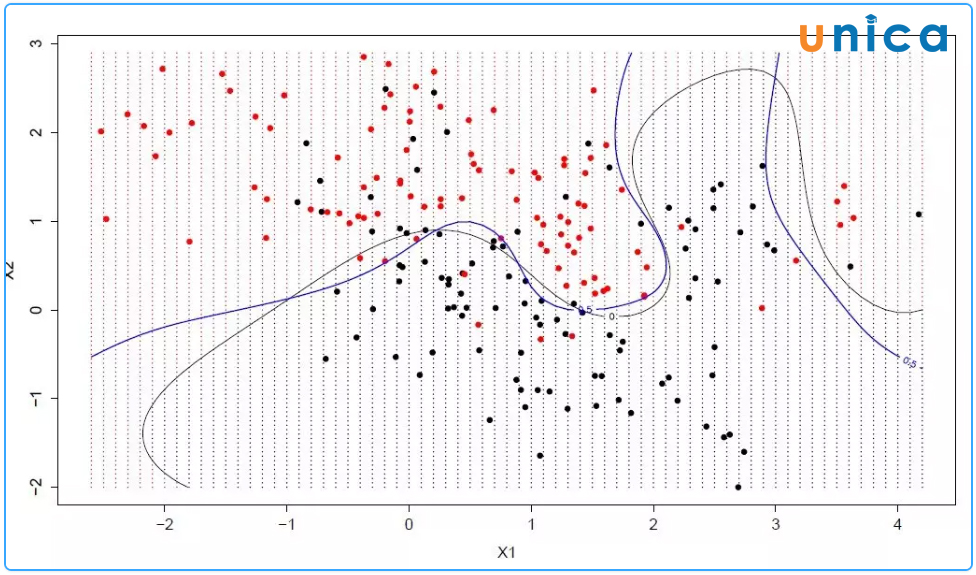
Thuật toán SVM
6.5. Thuật toán Naive Bayes
Naive Bayes là một thuật toán trong Machine Learning dùng để phân loại dữ liệu. Nó dựa trên luật Bayes và được gọi là "Naive" (ngẫu nhiên) vì nó giả định rằng tất cả các đặc trưng đầu vào là độc lập với nhau.
Cách hoạt động của Naive Bayes:
- Tính xác suất: Đầu tiên, chúng ta tính xác suất của mỗi lớp dữ liệu xảy ra dựa trên dữ liệu huấn luyện.
- Tính xác suất của các đặc trưng: Tiếp theo, chúng ta tính xác suất của từng đặc trưng trong dữ liệu mới dựa trên dữ liệu huấn luyện.
- Tính xác suất của lớp dữ liệu cho dữ liệu mới: Cuối cùng, chúng ta tính xác suất của từng lớp dữ liệu cho dữ liệu mới dựa trên xác suất của lớp dữ liệu và xác suất của các đặc trưng.
Naive Bayes là một thuật toán đơn giản và nhanh chóng, nó có thể hoạt động tốt với dữ liệu có kích thước lớn và có nhiều lớp dữ liệu.
Thuật toán Naive Bayes
6.6. Thuật toán K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) là một thuật toán trong Machine Learning dùng để phân loại hoặc hồi quy dữ liệu.
Cách hoạt động của KNN:
- Đầu tiên, chúng ta xác định số lượng "k" là số lượng điểm dữ liệu gần nhất sẽ được sử dụng để xác định lớp dữ liệu của một điểm dữ liệu mới.
- Tiếp theo, chúng ta tính khoảng cách giữa điểm dữ liệu mới và tất cả các điểm dữ liệu trong tập huấn luyện.
- Cuối cùng, chúng ta chọn k điểm dữ liệu gần nhất và sử dụng phần lớn số lượng điểm dữ liệu trong k đó để xác định lớp dữ liệu của điểm dữ liệu mới.
KNN là một thuật toán đơn giản và dễ sử dụng, nó có thể hoạt động tốt trong các tình huống phân loại hoặc hồi quy dữ liệu có kích thước nhỏ và đơn giản. Nó cũng có thể hoạt động tốt với dữ liệu có số chiều.
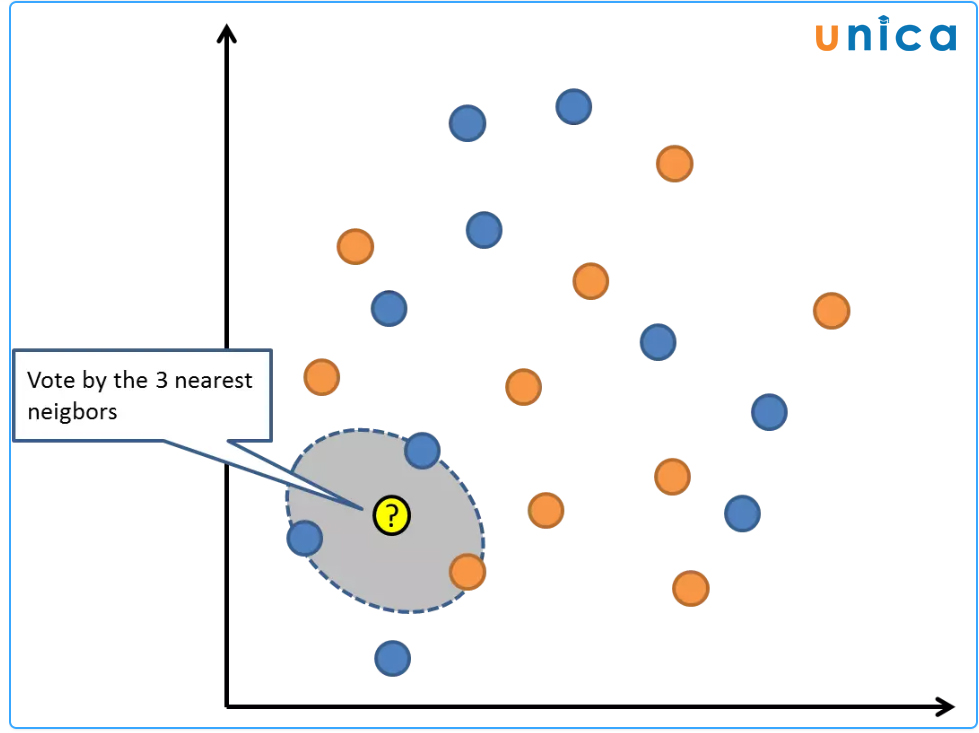
Thuật toán K-Nearest Neighbors (KNN)
6.7. K-Means
K-Means là thuật toán dùng để giải quyết các vấn đề phân cụm. Các tập dữ liệu được phân loại thành một số cụm cụ thể (gọi là K) theo cách mà tất cả các điểm dữ liệu trong một cụm là đồng nhất và không đồng nhất với dữ liệu trong các cụm khác.
Cách hoạt động của K-Means:
- Chọn số lượng nhóm (k) muốn gom.
- Chọn ngẫu nhiên k điểm dữ liệu trong tập dữ liệu làm trung tâm của các nhóm.
- Phân các điểm dữ liệu còn lại vào nhóm mà trung tâm của nhóm đó gần nhất.
- Tính toán trung tâm mới cho mỗi nhóm bằng cách tính trung bình cộng của các điểm dữ liệu trong nhóm đó.
- Lặp lại bước 3 và 4 cho đến khi trung tâm của các nhóm không thay đổi nữa hoặc đạt đến số lần lặp tối đa đã chọn.
K-Means là một thuật toán phổ biến và dễ sử dụng cho việc gom nhóm dữ liệu. Nó hoạt động tốt với dữ liệu có số chiều thấp và có cấu trúc nhất định. Tuy nhiên, K-Means có một số hạn chế về độ chính xác và khả năng xử lý dữ liệu không giống nhau.
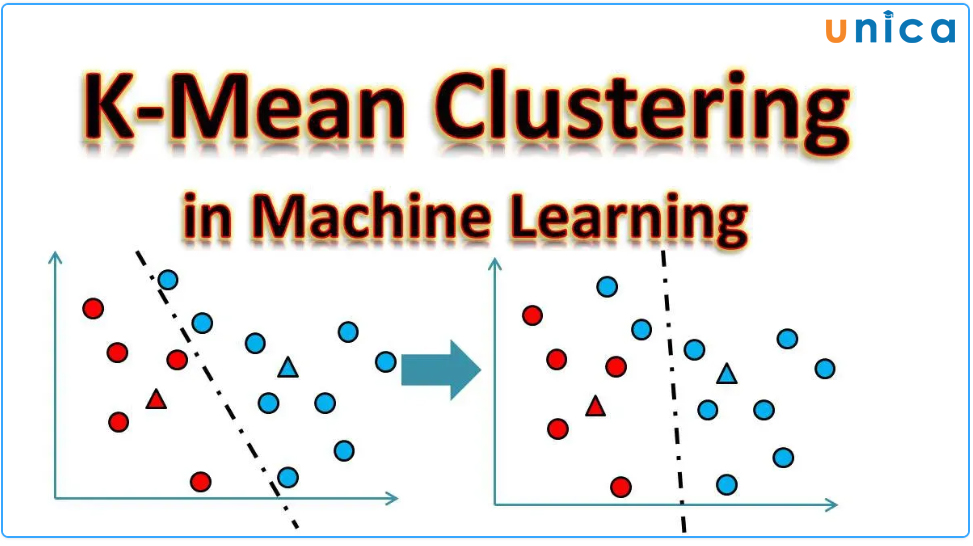
Thuật toán K-Mean
6.8. Thuật toán Random Forest
Random Forest là tập hợp các Decision Tree. Điều này có nghĩa là nó dựa trên việc tạo ra một tập hợp các cây quyết định và sau đó tạo ra một dự đoán dựa trên phần tử được chọn từ đó.
Các cây quyết định được tạo ra trong một Random Forest được xây dựng sử dụng một phương pháp gọi là "bagging". Bagging là việc tạo ra một tập hợp các mẫu ngẫu nhiên từ tập dữ liệu ban đầu và sau đó sử dụng mỗi mẫu để xây dựng một cây quyết định riêng.
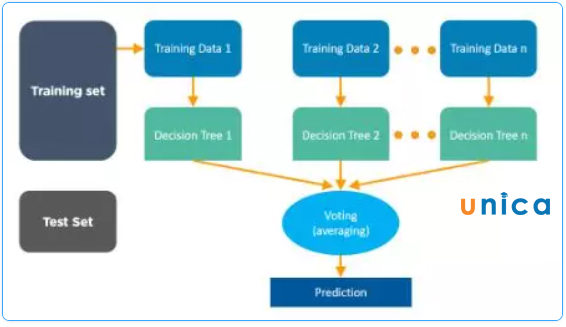
Thuật toán Random Forest
6.9. Thuật toán Dimensionality Reduction (Thuật toán giảm kích thước)
Dimensionality Reduction (Giảm số lượng kích thước) là một khái niệm trong Machine Learning và Data Science, nó đề cập đến việc giảm số lượng chiều của dữ liệu đầu vào để cải thiện hiệu suất và tính dễ sử dụng của các thuật toán học máy.
Có hai loại chính của thuật toán giảm số lượng kích thước:
- Projection-based Dimensionality Reduction: Giảm số lượng kích thước dựa trên việc chuyển đổi dữ liệu từ một không gian cao chiều sang một không gian thấp chiều bằng cách sử dụng một bảng chuyển đổi. Ví dụ, Principal Component Analysis (PCA) là một trong những thuật toán Giảm số lượng kích thước dựa trên Projection.
- Manifold Learning-based Dimensionality Reduction: Giảm số lượng kích thước dựa trên việc tìm kiếm một bề mặt mới (gọi là manifold) trong không gian dữ liệu cao chiều, và sau đó chuyển đổi dữ liệu vào không gian thấp chiều này. Ví dụ, t-SNE là một trong những thuật toán Giảm số lượng kích thước kích thước dựa trên Manifold Learning.
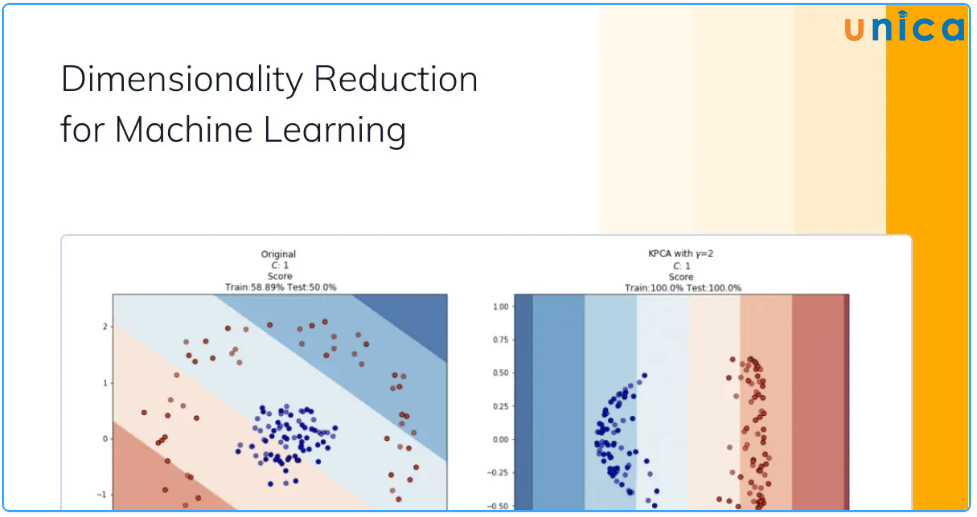
Thuật toán Dimensionality Reduction (Giảm số lượng kích thước)
6.10. Thuật toán Gradient Boosting và thuật toán AdaBoosting
Gradient Boosting và AdaBoost là hai thuật toán Boosting trong Machine Learning, được sử dụng để tăng cường độ chính xác của các mô hình phân lớp hoặc hồi quy.
- Gradient Boosting: Gradient Boosting là một thuật toán Boosting dựa trên việc tạo ra nhiều mô hình đơn giản và sau đó nối chúng lại để tạo ra một mô hình phức tạp hơn. Mỗi mô hình mới được xây dựng để hỗ trợ các điểm dữ liệu mà các mô hình trước đó không hề dự đoán chính xác. Gradient Boosting sử dụng hàm mất mát gradient để tìm ra mô hình tiếp theo.
- AdaBoost (Adaptive Boosting): AdaBoost là một thuật toán Boosting đầu tiên và là một trong những thuật toán Boosting phổ biến nhất. Nó tạo ra nhiều mô hình đơn giản và sau đó nối chúng lại để tạo ra một mô hình phức tạp hơn. AdaBoost tạo ra mỗi mô hình đơn giản bằng cách sử dụng trọng số cho mỗi điểm dữ liệu, với các điểm dữ liệu mà các mô hình trước đó không hề dự đoán chính xác sẽ có trọng số cao hơn.
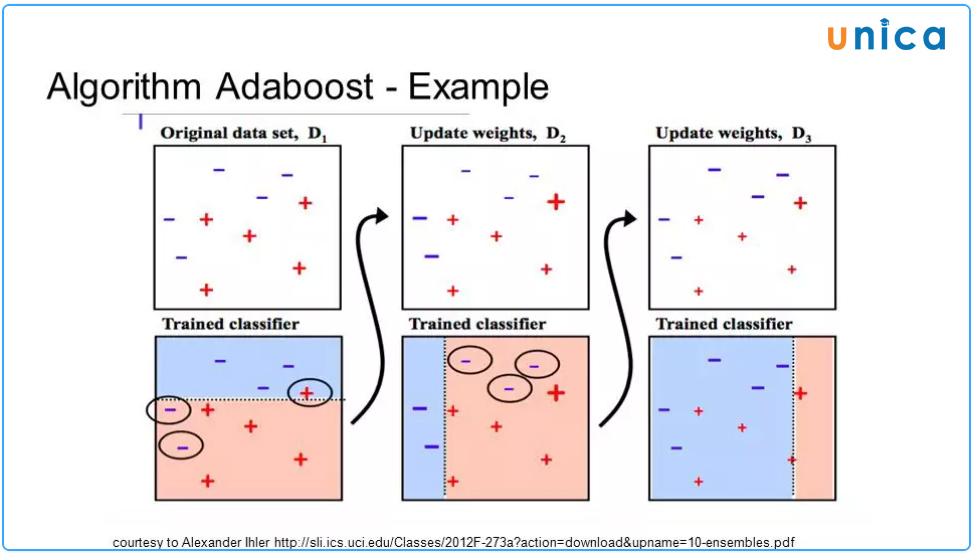
Thuật toán Gradient Boosting và thuật toán AdaBoosting
7. Ứng dụng của Machine Learning
- Speech Recognition: Machine Learning dùng để nhận dạng giọng nói máy tính, giọng nói tự động (ASR) hoặc chuyển giọng nói sang văn bản. Ứng dụng này cho phép người dùng có thể dịch giọng nói của con người sang định dạng chữ viết.
- Customer Service: Chatbots trực tuyến đang thay thế hành vi của người dùng trong hành trình của khách hàng. Đồng thời nó còn thay đổi cách chúng ta nghĩ về một loạt hành động trên các Website và các nền tảng xã hội.
- Computer vision: Machine Learning giúp máy tính có thể lấy thông tin từ hình ảnh kỹ thuật số, Video, sau đó thực thi thành động thích hợp.
- Recommendation Engines: Ứng dụng này cho phép sử dụng dữ liệu hành vi tiêu dùng trong quá khứ để khám phá các xu hướng dữ liệu nhằm mục đích phát triển các chiến lược Cross-sell hiệu quả hơn.
- Automated stock trading: Được ứng dụng nhằm mục đích tối ưu hóa danh mục đầu tư chứng khoán, các nền tảng giao dịch do trí tuệ nhân tạo điều khiển để giao dịch mỗi ngày được thực hiện mà không cần đến sự can thiệp của con người.
- Fraud Detection: Ngân hàng có thể sử dụng máy học để phát hiện các giao dịch đáng ngờ.
8. Một số câu hỏi thường gặp về Machine Learning
8.1. Ví dụ về Machine Learning?
- Dự đoán giá nhà: Machine Learning có thể được dùng để dự đoán giá nhà dựa trên các thông số như diện tích, vị trí, số phòng ngủ.
- Dự đoán trạng thái thị trường: Machine Learning được dùng để dự đoán trạng thái thị trường chứng khoán dựa trên các thông số giao dịch và tình hình kinh tế.
- Nhận dạng giọng nói: Machine Learning có thể nhận dạng giọng nói của một người để xác minh tài khoản hoặc đảm bảo an toàn khi giao dịch.
8.2. Sự khác biệt giữa AI và Machine Learning
AI là một khái niệm rộng hơn và bao gồm nhiều lĩnh vực khác nhau, bao gồm cả ML. AI là một khoa học về trí tuệ nhân tạo với mục đích tạo ra máy tính có thể tự động hoạt động giống như con người.
ML là một phần của AI với mục đích là tạo ra máy tính có thể học từ dữ liệu và tự động thay đổi kết quả của nó dựa trên dữ liệu đó. ML sử dụng các thuật toán và kỹ thuật để học từ dữ liệu và dự đoán kết quả.
Tóm lại, AI là một khái niệm rộng hơn bao gồm nhiều lĩnh vực, trong đó ML là một trong số đó. AI cố gắng tạo ra máy tính hoạt động giống như con người, trong khi ML cố gắng tạo ra máy tính học từ dữ liệu và tự động thay đổi kết quả của nó.
8.3. Machine Learning có khó không
Machine Learning là môn học đòi hỏi người dùng phải có những kiến thức liên quan đến toán học, các thuật toán và lập trình. Tuy nhiên nếu bạn có đam mê, thì Machine Learning sẽ trở nên vô cùng thú vị. Hiện nay, có rất nhiều tài nguyên và công cụ trực tuyến miễn phí để có thể học Machine Learning, bao gồm: bài giảng, dữ liệu và bài tập thực hành. Ngoài ra, bạn có thể tìm thấy các khóa học trực tuyến bởi các chuyên gia giảng dạy hàng đầu để việc học trở nên đơn giản hơn.
9. Tổng kết
Như vậy thông qua bài viết trên đây, Unica đã cùng bạn tìm hiểu về Machine Learning là gì, cách thức hoạt động và phân loại. Ngoài những kiến thức trên, nếu bạn muốn tìm hiểu chi tiết về AI thì có thể tham khảo khóa học chat GPT trên Unica nhé.
Cảm ơn và chúc các bạn thành công!


Bài liên quan
 Top 9 ứng dụng giả ChatGPT gây ảnh hưởng đến người dùng
Top 9 ứng dụng giả ChatGPT gây ảnh hưởng đến người dùng
 Chat GPT là gì? Lợi ích và nguyên lý hoạt động của ChatGPT
Chat GPT là gì? Lợi ích và nguyên lý hoạt động của ChatGPT
 Tư duy logic là gì? 8 phương pháp rèn luyện tư duy logic cho trẻ
Tư duy logic là gì? 8 phương pháp rèn luyện tư duy logic cho trẻ
 Top 11 công cụ AI tốt nhất hiện nay
Top 11 công cụ AI tốt nhất hiện nay
 Ứng dụng của ChatGPT trong lĩnh vực giáo dục
Ứng dụng của ChatGPT trong lĩnh vực giáo dục
 Mẹo tận dụng sức mạnh của Chatgpt để nâng cao hiệu quả công việc
Mẹo tận dụng sức mạnh của Chatgpt để nâng cao hiệu quả công việc

_m_1677227558.jpg)





